PDFファイルから文章を抽出するあれこれ。画像化されているやつはOCRをかけることになるが、本記事では対象外。Mac環境下で実行。
大きくわけて、コピペする、Adobe Reader DCを使う、pdftotextを使う、pythonのpdfminer.sixを使う、のパターンで。
ビューアで開いてコピペ
言わずもがな。PDFファイルを開いて、ビューアーからコピペする。原始的だけれど、なんだかんだ言ってそこそこの精度。
Adobe Reader DCの機能を使う
Adobe Reader DCは最近何かとお金を取るようになったらしく、インターネットで検索した情報を元にやってみると、その機能が有料化されていることがしばしばある。が、テキストの抽出は今のところ問題ないらしい(Word変換などはお金がかかる)。
「ファイル」→「その他の形式で保存」→「テキスト」と選択すると、テキストのみ抽出できる。
ファイルが1つだけで、GUIが使える環境ならこれが一番楽。
pdftotext
コマンドラインでのやり方として、pdftotextを使う方法がある。pdfを扱うライブラリpopplerをインストールする。
brew install popplerすると、以下のようなコマンドが使えるようになる。
pdftotext test.pdf日本語の扱いでエラーが出たら「pdftotextでPDFを文字列化 | IT研究所」を参考に。
-layoutオプションをつけることで、pdfのレイアウトを考慮したようなテキストファイルにすることができるが……むしろ使いづらいか。
ただこれを使うなら、次のpdf2txt.pyのほうが良いかな、と。
pdf2txt.py
pythonで実装されている、pdfminer.sixのpdf2txt.pyを使ってもできる。レイアウトを考慮した再現度が高い。pip install pdfminer.sixでもインストールできるが、pdf2txt.pyを実行するとエラーが出るので、公式サイトからダウンロードしてインストールする。公式サイト→「pdfminer.six 20170720 : Python Package Index」。ダウンロードしたら、解答して、setup.pyを実行する。
python setup.py installこれでpdf2txt.pyが使えるようになる。
pdf2txt.py test.pdfデフォルト標準出力。そこそこ時間がかかるが、Adobe Readerのテキスト抽出よりも綺麗かなと思う。何と言ってもコマンドラインで完結するのが大きい。
-nまたは--no-laparamsオプションをつけることで、レイアウトを無視して高速に結果を得られるものの、それだと精度が悪い。


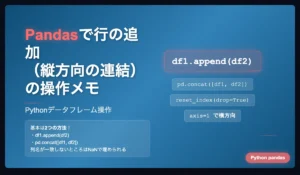




コメント