AIプログラミング普及のために何が必要か考えている。エンジニア視点だとここまできたらもう誰にでもできるではないか、と思う一方で実際に踏み出せるかというと難しい気がする。
それで、ちょうど今日新しく作ろうと思ったWebアプリについて、そのプロンプトを記録して公開することで、人の参考になるのではないかなぁと思った。
まぁさすがに現段階でまるっきりプログラミング初心者向けというわけにはいかないのだけれど、なにかしら少しでも経験があればわかるのではないかな🤔
つくるアプリ・電子書籍をWebブラウザベースで管理・閲覧するWebアプリ
実例で見るのが一番いいだろう。今回作るWebアプリは、家の電子書籍をWebブラウザ上で読むためのものだ。
僕はかなり早い段階から電子書籍に関心があったため、家には裁断機とドキュメントスキャナがあり、手持ちの本はすべてPDFまたはZIP化している。また、マイナーだが技術評論社などDRMフリーの電子書籍ストアも技術系にはある。
それで気がつくと数千冊…いや…万…の本があるのだけれど、この電子書籍の管理はけっこう面倒臭い。今はCalibreというソフトウェアを使っているが、これはたいへん多機能で良いソフトなのだけれど、管理がベースでビューア機能はあまりよくない。特に僕はWebブラウザでそのままPDFやZIP(JPGなど画像ファイルを固めている)を読みたいのだけれど、その目的はかなり限定的にしか果たされない。エラーもたまに起きる。本の並べ方もあまり融通がきかない。つまり、僕の要件とあまりマッチしていない。
漫画ビューアなどは他にもあるものの、僕が読みたいのはそれだけではないし、自分の要件に合わせた電子書籍管理・ビューアアプリを作ろうと思った。
最初のプロンプトを書き上げる
アプリの挙動をざっくりイメージする
なんとなくイメージする。Webブラウザで開く。iPadでもPCでも開ける。本棚がある。本棚の中にはシリーズがあって、その中に本がある。特定の条件…作者名とか…あとあるいはジャンルとか…そういうのでサクッとフィルタして、目当ての本が探せる。そしてそのまま読める。しおりも挟める。読んだ本は読んだチェックをつけたり、感想を残したりする…。あ、なんか本棚ロックしたりとか、あと限定的に共有とかもできるといいな…。非表示…非表示はいらないかな…ロックと根本的に同じ気がする。あとは気になったところを適当になおしていこう…。
なんかこんな感じのことを考えた。
ざっと書き上げる
そんで最初に書き上げたプロンプトがこれ。
Webブラウザで電子書籍を管理・閲覧するWebアプリを作成する。
セルフホストのWebアプリであり、LAN内のPCから閲覧することを想定している。
電子書籍とは
- データの実体: pdf、epub、または.cbz(jpegなど画像ファイルをzipにしたもの) である
- 単発ものとシリーズもの(小説や漫画など)が存在するため、ナンバリングが必要
データは実体としてファイルシステムに保存される。
電子書籍は「シリーズ」と「ボリューム」に分かれる。
「シリーズ」とボリュームは共通して以下のメタデータを保持する。
これらのメタデータについて、ボリュームはシリーズと同じ値をデフォルトとして持つが、個別に設定することも可能。
- 作者(複数登録可能)
- タイトル
- タグ(複数管理可能)
- サムネイル
- メモ(感想など)
「ボリューム」は以下をメタデータとして持つ。
- ボリューム数(ナンバリング)
電子書籍は「本棚」で管理される。
本棚は複数作ることができる。
Webアプリは以下ができる。
- Webブラウザから本棚を作成できる
- Webブラウザから本棚を削除できる
- Webブラウザから本棚を更新できる
- 本棚はパスワードでロックすることができる
- Webブラウザから本棚に電子書籍を登録する
- 同じ書籍を複数の本棚に登録できる
- Webブラウザから本棚に電子書籍を削除できる
- Webブラウザから本棚の電子書籍のメタデータを編集できる
- Webブラウザから本棚ごとにタイトルや作者名やタグやメモの部分一致検索ができる
- Webブラウザから本棚ごとにタグでフィルタできる思いついたまま書いた。見返すと手を入れたくなるが、こんなもんでいいというライブ感でそのまんま掲載する。
ここにはいくつかの要素がある。
- ユースケースはLAN内の自分用。つまりSaaSみたいにガチガチの認証ロジックとかいらない。
- データはファイルシステムに存在すること。
- ざっくりと本棚、シリーズ、ボリュームのエンティティがあること。また、その繋がり方。
- 本棚、シリーズ、電子書籍は基本的なCRUD機能をWebUIで持つ
- 検索の存在などでUIの雰囲気をふわっと伝える
端的に言うと、アクセス範囲(スコープ)とデータ構造、永続的保存と最低限の機能についてざっくり記述している。要件定義というか基本設計の最初のドラフトって感じ。これでいけるんだから大したもんだよ。
書かなかったこと
多分書いたことよりも、何を書かなかったのかほうが重要かなと思う。
- 言語の選定など、どのように実装するか(How)は指定していない
- 見た目の指定をしていない
- 細かいビュー系の機能を書いていない
- ソート機能や直近読んだ本の表示などはほしかったが、後でいいやと思った
- 異常系書いてない
書いたことがざっくりしたWhatなら、書かなかったことはHowと細かなWhat。Howはエンジニアだと色々指定したくなるかもしれないんだが、しないほうがいいと思う。
Whatについても、コアのデータモデルさえあれば、ほとんどブラッシュアップでいける。最初からあれこれ書くもんじゃない。しおり機能とか最初から作ろうとしない。
できたもの
最初だけOpus 4.6使った模様。Proプランでゲージ20%ほど消費した😢
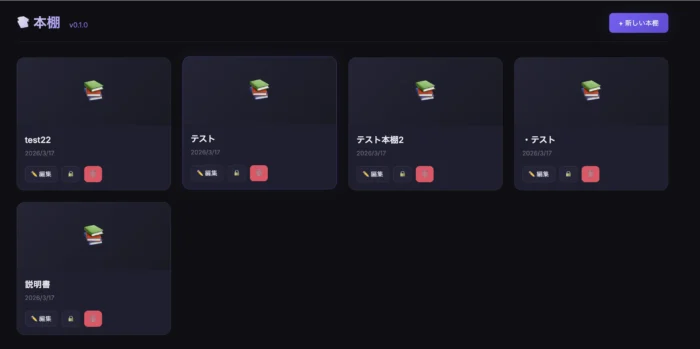
見た目はいかにもAntigravityで作りましたって感じ。多分Antigravity使ってる人は一発でわかる気がする。なんかだんだん傾向見えてきた。まぁでもやりたいことができることが一番だ。一通りのCRUDができることは確認した。
ちなみにこの後しばらくしたら、Opus 4.6の残量完全に消えたので、20%っていうか30%くらい使ってたかもしれない。
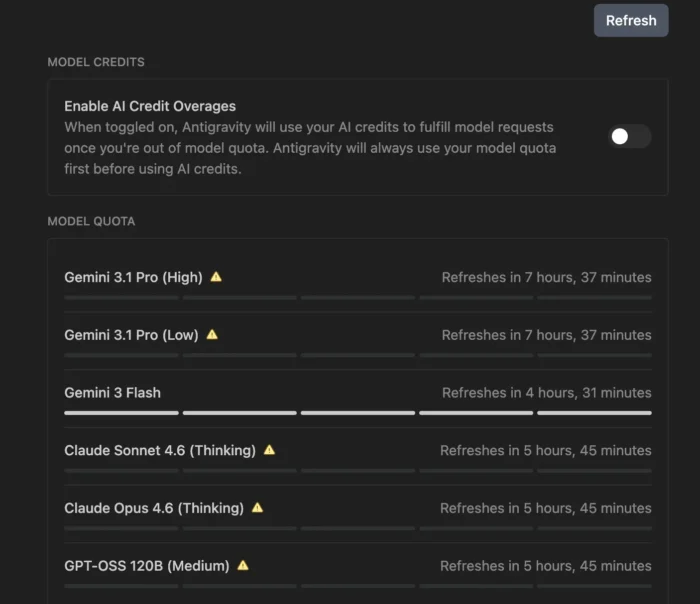
いっぱい使えることだけがいいところだったのに、3月に入って強烈に改悪されてしまった。多分これからもどんどん使えなくなっていくのだろう。
あとは適当に改修していく
本当は最初のプロンプトをばっと出して、その後こんな感じで改修していくみたいな記事にしようと思ったのだが、いざ書き始めると、伝えるうえで一番大事というかほぼここだろってのが最初のプロンプトに思えた。
まぁもちろんこのまんまだと使えない。ファイル名やディレクトリ構造とかどう保存されるのかとかも謎だし、っつか各フォーマットで読めるかとか、確認すること多いよな。まぁでもそういうのは使っていきながらブラッシュアップしていけばいい。ブラッシュアップはGemini 3 Flashで十分。2週間くらい使いながらコミットを50ばかり続ければ、いつのまにかそれなりのもんになってる。
ってか冷静に考えると本の単位をボリュームにしたのは奇妙な感じがするし、変えようかな。まぁこういう人間がやると事故必至みたいなのもAIは割と正確にやってくれるんよね。データベースのスキーマ変更はけっこう注意深くやらないといけないポイントなのは変わらんのだけど。
まぁ基本は大して変わらんのよ。プロンプトとか言ってるけど要はただ設計してんのよこれ。でもめっちゃ早いよね。今はこんな感じでアプリ制作している。もう今さらプログラミングする気になれない。みんなそうしてるんだろ。廃業だよ。








コメント