確かにDify色々いじれるのは便利。
目次
環境
以下を実行済みとし、環境も同一。
あわせて読みたい


セルフホストでDify + ローカルLLM + RAG
今さらRAGやる。サクッと試すならDifyかなということで、またローカルLLMとローカルデータベースにこだわりを見せてやる。 環境 M2 Pro Mac mini 12コアCPU、19コアGPU ...
手順
環境変数の設定
以下を環境変数として設定する。ナレッジのドキュメントを選択すると、左下に「サービスAPI」があるので、そこを見るとURIがわかる。シークレットキーを発行することもできる。
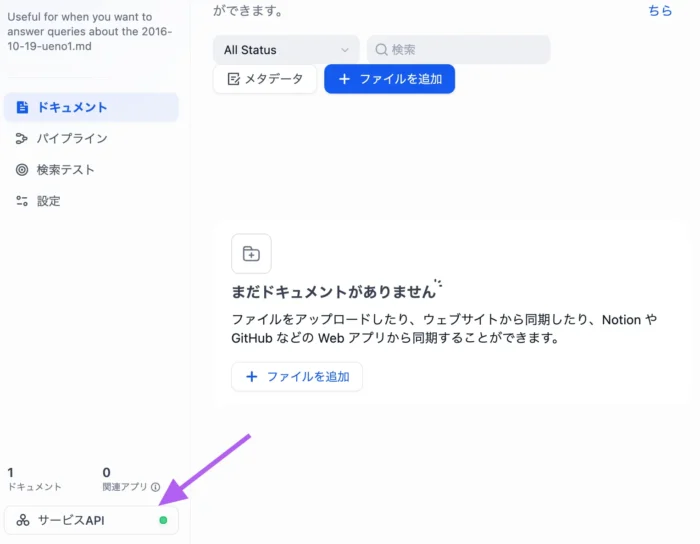
DIFY_API_BASE:http://ベースURL:ポート/v1DIFY_DATASET_ID: ドキュメントを選択したURLのdatasets/{ID}のIDの部分DIFY_KNOWLEDGE_API_KEY
1個ずつアップロードするスクリプト
まずアップロード用のスクリプト。これは1つだけアップロードする。この手の糞コードは全部AIになった。チャンク識別子はデフォルトの\n\nとなる。
#!/usr/bin/env python3
import argparse
import os
import json
import requests
from pathlib import Path
# --- 設定 ---
API_BASE = os.environ.get("DIFY_API_BASE")
DATASET_ID = os.environ.get("DIFY_DATASET_ID")
API_KEY = os.environ.get("DIFY_KNOWLEDGE_API_KEY")
def upload_md(md_path: str):
if not API_KEY:
raise RuntimeError("環境変数 DIFY_KNOWLEDGE_API_KEY が設定されてない。")
endpoint = f"{API_BASE}/datasets/{DATASET_ID}/document/create-by-file"
headers = {"Authorization": f"Bearer {API_KEY}"}
data = {
"indexing_technique": "high_quality",
"process_rule": {"mode": "automatic"}
}
with open(md_path, "rb") as f:
files = {
"data": (None, json.dumps(data), "text/plain"),
"file": (Path(md_path).name, f)
}
resp = requests.post(endpoint, headers=headers, files=files, timeout=120)
if resp.status_code == 200:
print(f"OK: {md_path}")
else:
print(f"NG: {md_path} ({resp.status_code}) -> {resp.text}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Upload one .md file to Dify Knowledge Base")
parser.add_argument("file", help="Path to markdown file")
args = parser.parse_args()
upload_md(args.file)
実行する。
python upload_md.py file.mdmd_filesディレクトリにあるmdファイルを全部やる場合はシェルスクリプトで以下。
find .md_files/ "*.md" -exec python upload_md.py {} \;5-10KBのアイテムを1600ほど(合計10MB弱)だったけど、けっこうすぐに利用可能になったね。
チャンク識別子を変える
process_ruleのmodeをcustomにする。たとえば、以下はMarkdownの##をチャンク識別子とした時のもの。
#!/usr/bin/env python3
import argparse
import os
import json
import requests
from pathlib import Path
# --- 設定 ---
API_BASE = os.environ.get("DIFY_API_BASE")
DATASET_ID = os.environ.get("DIFY_DATASET_ID")
API_KEY = os.environ.get("DIFY_KNOWLEDGE_API_KEY")
def build_process_rule(separator_regex: str | None) -> dict:
if not separator_regex:
return {"mode": "automatic"}
return {
"mode": "custom",
"rules": {
"pre_processing_rules": [],
"segmentation": {
"separator": separator_regex,
"max_tokens": 600,
"chunk_overlap": 80,
}
}
}
def upload_md(md_path: str, separator_regex: str | None):
if not API_KEY:
raise RuntimeError("環境変数 DIFY_KNOWLEDGE_API_KEY が設定されてない。")
endpoint = f"{API_BASE}/datasets/{DATASET_ID}/document/create-by-file"
headers = {"Authorization": f"Bearer {API_KEY}"}
data = {
"indexing_technique": "high_quality",
"process_rule": build_process_rule(separator_regex)
}
with open(md_path, "rb") as f:
files = {
"data": (None, json.dumps(data), "application/json"),
"file": (Path(md_path).name, f)
}
resp = requests.post(endpoint, headers=headers, files=files, timeout=120)
if resp.status_code == 200:
print(f"OK: {md_path}")
else:
print(f"NG: {md_path} ({resp.status_code}) -> {resp.text}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Upload one .md file to Dify Knowledge Base")
parser.add_argument("file", help="Path to markdown file")
parser.add_argument(
"--chunk-separator",
help=r"Regex for chunking (e.g. '(?m)^##\s+' or '(?m)^(##|###)\s+'). Empty string to use automatic chunking."
)
args = parser.parse_args()
default_regex = r"(?m)^(##|###)\s+"
separator = args.chunk_separator if args.chunk_separator is not None else default_regex
if separator == "":
separator = None
upload_md(args.file, separator)








コメント